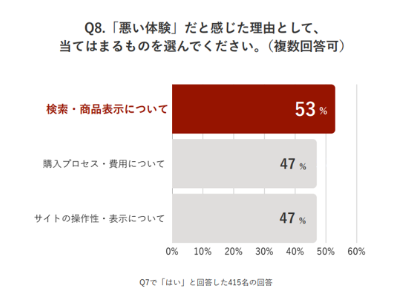

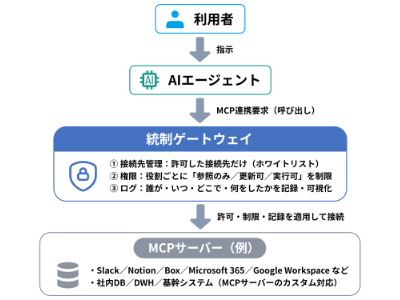


























会員登録無料すると、続きをお読みいただけます
![]()
新規会員登録無料のご案内
- ・全ての過去記事が閲覧できます
※プレミアム記事(有料)は除く - ・会員限定メルマガを受信できます
- ・翔泳社の本が買える!500円分のポイントをプレゼント
-
- Page 1
-
- Page 2
-
- Page 3
この記事は参考になりましたか?
- 水野貴明の“技術から学ぶ”アクセスログの読み方連載記事一覧
- この記事の著者
-

水野 貴明 (ミズノタカアキ)
1973年東京生まれ。バイドゥ株式会社勤務の兼業テクニカルライター。学生のとき に父親が買ってきたパソコン(マイコン)と出会い、コンピュータとの付き合い を開始。大学は有機化学、大学院では分子生物学を学ぶも、就職で再びコンピュータの道を進むことになった。その後インターネットの普及により、様々な方に出会う機会を得て1999年より執筆活動を開始。 http://d.hatena.ne.jp/mizuno_takaaki/
著書
『アクセス解析でホームページの集客を極める本』 水野 貴明著、 ソーテック社、2005年3月
『詳解RSS~RSSを利用したサービスの理論と実践』 水野 貴明著、ディー・アート、2005年8月※プロフィールは、執筆時点、または直近の記事の寄稿時点での内容です
この記事は参考になりましたか?
この記事をシェア