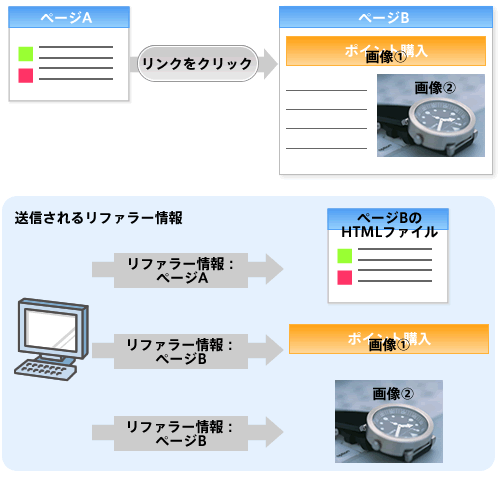
リファラー情報の仕組み
リンク元の解析に利用されているのがリファラー情報であるとわかったところで、続いてはリファラー情報はいったいどんなときに、どんな情報が送られるのかをもう少し詳しく紹介しておくことにします。
まず、リファラー情報が送られるケースと送られないケースについてです。リファラー情報は「参照元」、つまりアクセスしたURLを、いったいどこで知ったのかを表すものです。そのため、どこかのページに貼られたリンクがクリックされた際にだけ送られます。そしてリンクをクリックする以外の方法でページにアクセスされた場合にはリンク元は記録されません。
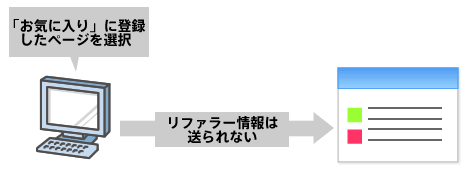
つまり、「お気に入り(ブックマーク)」に登録されているページをメニューから選んでアクセスした場合や、ブラウザのURL欄にURLを直接入力した場合などは、リファラー情報は送られてきません。アクセス解析サービス/ツールのリンク元解析の結果を見た場合に「ブックマークなど」や「不明」といった項目が含まれることがあります(というよりも、ほとんどの場合は含まれると思います)が、それはそうしたリファラー情報を含まないアクセスであったことを示します。
「ブックマークなど」と書かれていてもそれらがすべてお気に入り(ブックマーク)経由なのではなく、さまざまな理由によりリファラー情報が送られてこなかったアクセスがすべて含まれているのです。リファラーが送られない理由にはさまざまなものがあり、むしろ通常のサイトでは、お気に入りからのアクセスよりもそれ以外の理由によるもののほうがずっと多いはずです。その理由については、後ほどまた説明します。
また、解析結果に「不明」や「ブックマーク」といったリファラーがなかったことを示す項目がなかったとしても、おそらくそれは、そのサービス/ツールがリファラーの存在するアクセスだけからリンク元の集計を行なう設定になっているからです。つまり、本当にリンク元のないアクセスがほとんどなかったわけではありません。
なお、通常、Webベージにアクセスする場合、単にHTMLファイルをダウンロードするだけでなく、そこに含まれる画像などもあわせてダウンロードする必要が出てきます。そうしたHTMLファイルに含まれる画像(やCSSファイル、JavaScriptファイルなど)へのアクセスの場合、リファラー情報はどうなるのでしょうか。
リファラー情報は「そのURLをどこで知ったのか」を表す情報です。そして、そうしたHTMLファイル内で指定されたファイルの場合は、そのURLを知ったのは、それを指定しているHTMLファイル、ということになるので、リファラー情報にはこのHTMLファイルのURLが入ります。つまり画像ファイルへのアクセスの場合、リファラー情報にはその画像が貼り付けられているページのURLが入ることになるわけです。少しややこしいので図にすると、以下のようになります。