





































本格的な分析を始める前に「必ず」確認しておきたいこと
さて!第二回目は、本格的に分析を始める前に「必ず」確認しておきたいことを紹介していきます。
散々苦労して分析を終えて考察も書き終えて、ホッとしてると………
ある記憶がふとよみがえります!
「(ぁ!)………。」
「この期間は、元のデータが100倍の数値が入っているので差し替えが必要なんだーー!」
迫る終電、止まる空調、手に汗握る……今晩もタクシー自腹か…。嫌な記憶がよみがえります。こんな状況は「絶対」に避けたいですよね。私も絶対に嫌です。
しかし直前に、アレコレと焦ってはミスがミスを誘発してしまいます。そこでパッと、データに異常値がないか推測できたら嬉しいと思いませんか?
できます! できるのです!
「平均値」「中央値」「最大値」「最小値」といった基本統計量と呼ばれる値や、手元にあるデータの特徴を簡単に確認できる「ヒストグラム」にチャレンジしていきましょう。
- 平均値:「全データを合計」して「データの数」で割った値。ちなみにExcelの関数ではaverage()
- 中央値:「全データを小さい順番に並べてちょうど真ん中の値」。こちらExcelではmedian()
- 最大値:「全データ中で最も大きな値」Excelではmax()
- 最小値:「全データ中で最も小さな値」Excelではmin()
という訳で、前回の「Rの起動と準備」を参考にデータを読み込みましょう。
善は急げ! 早速、平均値を計算
早速、純広告のインプレッションの平均値を計算します。
mean(sample[,2:2])
と打ち込んでみましょう。
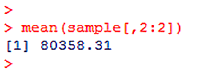
と表示されますね。ここで、
sample[,2:2]
は、2列目の変数の値全てを選択するという意味でした。続いて、
mean(sample[,3:3])
mean(sample[,4:4])
mean(sample[,5:5])
と、コピペして下さい。
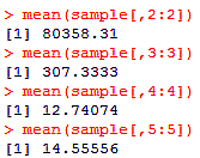
となります。ちなみに変数指定のやり方ですが、
mean(sample[,"純広告"])
mean(sample[,"リスティング"])
mean(sample[,"CV_純広告"])
mean(sample[,"CV_リスティング"])
や、
mean(sample[,'純広告'])
mean(sample[,'リスティング'])
mean(sample[,'CV_純広告'])
mean(sample[,'CV_リスティング'])
と、変数名をシングルクォーテションやダブルクォーテーションで囲んでもOKです。
補足ですがWordにはシングルクォーテションやダブルクォーテーションを自動的に全角にしてしまう可能性があります。Word2010ではファイル→オプション→文書校正→オートコレクトのオプション→’’を‘ ’に変更するのチェックを外すと解消されるようです)
と、ここまできて、
ん……………。確かに平均値は計算できてるが「全然便利に感じない」。というか、列選択とかメンドイし、そろそろコンソールを閉じたい、、、ですよね。閉じる前にコレを入力してみましょう!
summary(sample[,2:5])
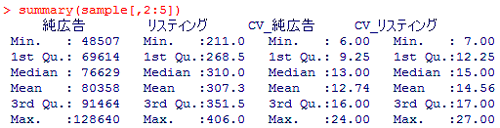
何やらまとめて一気に表示されました。Minは最小値、Meanは平均値、Maxは最大値であることは想像できます。では1st Qu、Median、3rd Quは??? 意味がわかりませんね。
簡単! 2015年2月10日「3つ」覚えて分析から視覚化まで即実践!Rでできるデータ分析講座開催
Rをインストールしたが、無骨なUIに「今日はこのへんで……」と、そっと閉じてしまった方にオススメです!
本講座では実機を使って「できるだけわかりやすく」グラフ化&データ分析をワークショップ形式で簡単に身に付けることができます。
