






































構造把握・予測・最適化が機械学習の基本工程
林氏はまた、実際のデータ分析工程についても解説を行い、「大きく分けて3段階ある」とその工程について語った。
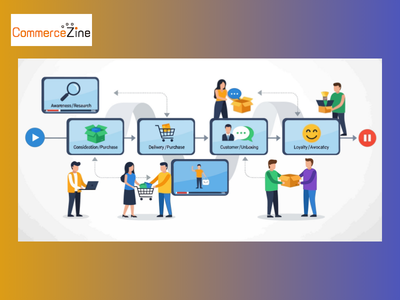
まずはデータを集計しての「構造把握」。データを見て現状を把握し、構造を理解することが主な目的だ。次が「予測」で、これまでの結果から起こり得る未来を見通す。最後が「最適化」となり、予測段階で出た策の中から選択すべき最適解を決定する段階である。
林氏はこの一連の流れをカーナビにたとえ、「渋滞や通行止め、高速道路の有無などの情報を収集し、どのルートが最も速いのか、安いのかを予測し、最終的にどんなルートを取るのか判断する」と説明した。

社内外のデータのすべてが分析対象。日に日に増え続けるデータの種類と量
「これまでは企業が保有しているデータの分析が中心だったが、今は社外のデータも積極的に利用する時代」と林氏は説明。そういった背景からブレインパッドでは、分析に利用するデータを3つに大別している。
1つは、顧客情報や商品情報など、企業が元々保有しているデータ。顧客IDに紐付いているこれらを、ここではオフラインデータと定義する。2つ目は、Webアクセスログデータ、ユーザーの行動を点数化したスコアリングデータ、スマートフォンの位置データなどのオンラインデータ。最後が外部データと呼ばれるもので、天候、ソーシャルメディアの利用履歴、各種統計情報などがこれにあたる。
他にも、IoTデバイスで収集したセンサーデータや他社を含めたサービスの利用履歴など、分析対象となるデータの種類と量は、日に日に増加しているのが現状だ。

