
















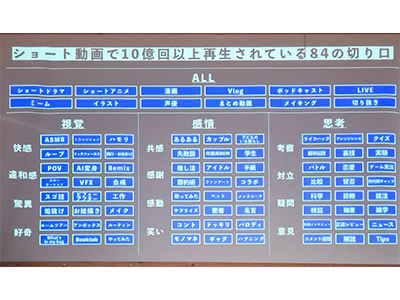












レシートの「表記ゆれ」問題をどう回避する?
新商品の売れ行きを初動で失速させないために、多くのマーケターは「顧客の購買傾向」「競合の状況」「市場のトレンド」「自社のターゲット」などに目を向ける。それらの根拠として購買データは有用だが、参照元によって得られる情報は限定されてしまう。

たとえば、クレジットカードの決済データを参照すれば「どこでいくら購入した」はわかるものの「何の商品を買った」はわからない。店舗のPOSデータからは顧客属性が読み取れない上、情報がチェーン店内に閉じている。会員カード情報では導入店舗以外の購買データがわからず、消費者パネルデータはデータ量や調査対象となる商品が限定的なのだ。
その点、ONEのレシートデータなら「誰がいつどこで何を買ったか」がわかるという。たとえば、Aさんがコンビニエンスストアでコーヒーを購入した後、スーパーで生鮮食品を購入し、ガソリンスタンドで給油をした場合、それらの連続した購買行動を追うことができる。

「あらゆるチャネルを横断して購買データを集められる点が、ONEの特徴の一つです。ある商品がいつどこでどれだけ買われているか、何と一緒にどんな人が買っているか、ということも分析することができます」(新井氏)
レシートデータを扱う難しさとして、新井氏は「表記のゆれ」を挙げる。たとえば同じ「ONEビール」という商品でも、チェーンや店舗によって「ONE BEER」「ワンビール」など、レシート上の記載が異なるためだ。

「当社では、画像から文字を起こすOCR(Optical Character Recognition)を用いた独自のデータ基盤によって、レシートの印字内容をデータ化しています。それらのデータを機械学習モデルに学習させながら、文字列を商品名・カテゴリー・品番・店名などに構造化しているのです」(新井氏)
ペルソナの迅速な修正でリピート購入者数を伸長
ここで新井氏は、酒類メーカーA社の事例を紹介する。新発売するアルコール飲料のペルソナとして、次のような特徴が設定されていた。

設定したペルソナ通りの人物が新商品のファンとなり、リピート購入しているのか。その点を確認するため、A社ではONEのデータを基に短期間でリピート購入しているBさんを深掘りした。
ONEのデータなら、性別・年齢・居住地・子どもの有無など、アプリに登録された情報に加えて、レシート情報から出かける場所がわかる。Bさんは、平日に新橋周辺と錦糸町周辺で購買することが多いため、このエリアが職場と自宅に近いと考えられる。一方で、週末は小田原や鎌倉など海の近くで過ごしていた。また、SNSで話題のカフェを訪れたり、ヘルシーな食品を購入したりしていたそうだ。
Bさんを深掘りしたことにより、新商品のアルコール飲料がアクティブなシーンでも好まれるポテンシャルを備えていることがわかった。そこでA社はペルソナを迅速に修正。リピート顧客を確実に補足するためのプロモーションを展開していった。

「このアルコール飲料は発売後も徐々に市場へ浸透し、ONEでの購入ユーザー数や購買が確認できるレシート数、取扱店舗数が右肩上がりに増えていきました。また初動では購入者数と購入数がほぼ1:1でしたが、3ヵ月後には約5.6万人のユーザーに8.7万点購入され、一人あたりの平均購入数は1.4倍に伸長。リピート購入されていることが観測できました」(新井氏)

