


























ディープラーニングの得意分野
第2回で紹介した事例の中で、「顔認識による感情分析」にディープラーニングが用いられていることを伝えた。そして第1回で紹介したImageNetやGoogleの事例も画像認識の話題である。ディープラーニングの得意分野は今のところ画像認識・音声認識・自然言語処理が中心で、ディープラーニングの活用事例として紹介されているものはほとんどがこの領域だ。
逆にいうと、ディープラーニングをそれ以外の分野に適用して成果をあげようというのはまだ手探り状態という認識である。
なぜ画像・音声・言語が得意なのか。よく聞く話かもしれないが、ディープラーニングは、これまで人が設計していた特徴量の抽出からコンピュータが行う。画像・音声・言語というのは、人間がどのようにして内容を認識しているのか、説明しにくいものだ。
例えば「原田」という人間に遭遇した時に、自分はどうやって「あ、原田だ。」と認識するのか。顔の各パーツ、その総合的なバランス、体系、髪型……などだろうか。では、総合的なバランスとは何か? 各パーツといっても、例えば「つぶらな目」はどう量的に表現すればいいのか。目の面積だろうか、それとも顔の面積に対する比率だろうか。さらに、至近距離の場合と遠くのほうに見かけた場合とでも見ている特徴は異なるはずだ。
このような「説明しにくい領域」は、「人間が特徴量を設計しにくい領域」(あるいは設計が極めて専門的な領域)でもある。人間が設計しにくい特徴をコンピュータで処理して抽出してしまうから、ディープラーニングはこのような領域において人間が特徴量を設計するより高い精度を出しやすい。
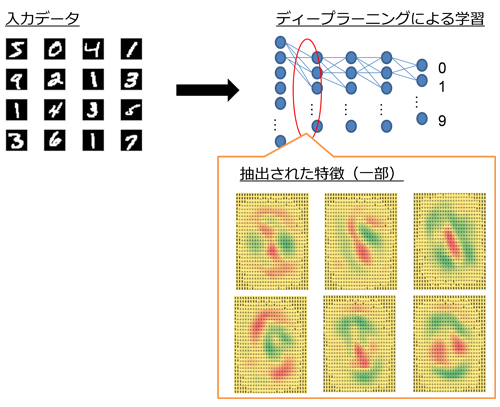
ちなみに抽出された特徴は人間が見ても、多くの場合は意味が分からない。当社のデータサイエンティストがディープラーニングを実装して遊んでいたのだが、以下はその際の学習で抽出された「特徴」の一部だ。入力データはMNISTという手書き数字のデータを使用している。1つ1つが「数字の特徴」を表している。数字に見えるものも一部あるが、ほとんどは言われなければ分からないだろうと思う。
では、上記のような特徴量を設計しにくい領域とは逆に、「特徴量を設計しやすい領域」ではどうか。この場合、人が設計する特徴量に対して、ディープラーニングに相対的に大きな優位性は出ないため(今のところは)、あまり活用事例が見られない。
例えば、購買履歴データ中心のCRM系の予測などがあげられる。「毎月1万円分購入している顧客の、翌月の購入金額はいくらだろう?」という予測に関していえば、人による設計とディープラーニングの精度に差は出にくい。
当社の取り組みでも、冒頭のオーディエンス拡張について内部の手法だけをディープラーニングに置き換えて精度が向上するか試行したところ、やや精度は向上した。しかし、パラメータ設定の難易度やシステムとして汎化できるか、また処理負荷が耐えうるかを考えると、実用にはまだ踏み切れていない状況だ。入力データの見直しなども含めて検討しなければ、このような領域では目立った成果をあげるのは難しそうだ、というのが現状の所感である。
