
















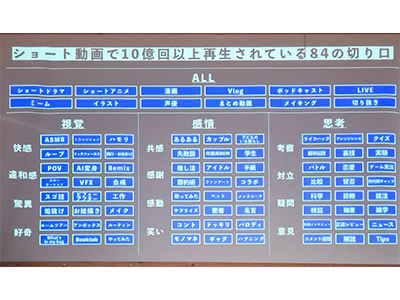

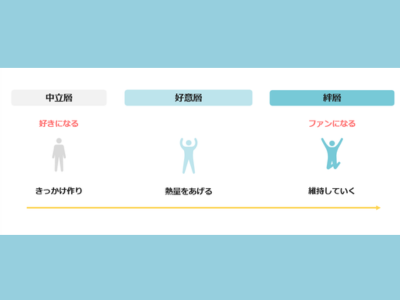











会員登録無料すると、続きをお読みいただけます
![]()
新規会員登録無料のご案内
- ・全ての過去記事が閲覧できます
※プレミアム記事(有料)は除く - ・会員限定メルマガを受信できます
- ・翔泳社の本が買える!500円分のポイントをプレゼント
-
- Page 1
-
- Page 2
-
- Page 3
この記事は参考になりましたか?
- この記事の著者
-

伊藤 友治(イトウ トモハル)
株式会社インテージ 事業開発本部 先端技術部 製造小売業、専門商社を経て、インテージに入社したデータサイエンティストです。主にマーケティング課題解決に対して、所謂データサイエンスの力でお手伝いしてきました。現在、画像解析系のAI技術をマーケティング領域で利活用すべく、いくつかのプロジェクトを担当してい...
※プロフィールは、執筆時点、または直近の記事の寄稿時点での内容です
この記事は参考になりましたか?
この記事をシェア