

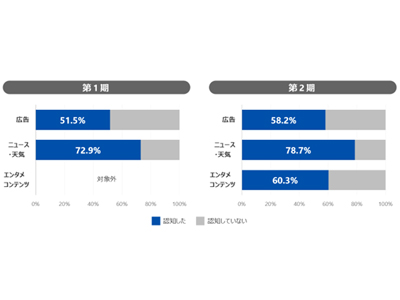


























プライベートDMP活用の鍵は「探索型分析=セグメント構築」にあり
V.1.0の構成は以下です。
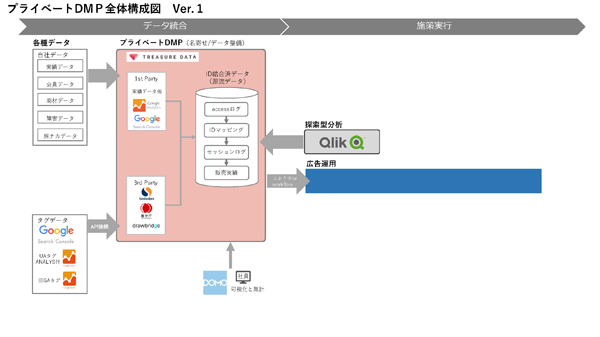
V.1.0はTreasure Dataへ向けた、販売データとWebログデータの統合です。QlikViewを導入して探索型分析ができるようになることをゴールに据え、販売データ側の14基の個別DB群とWebログをつなげています。ここまでを1stタームとして3ヵ月で構築し、4ヵ月目には探索型分析がスタートしました。
短期間で形にしたものの、そこには大変な苦労がありました。ばらばらに存在するデータのクレンジングやテーブル統合といった、現状調査と結合テストの繰り返しは、スケジュールが見えづらく、かつ地味な仕事です。データ基盤チームはV.1.0のスコープを分析要件から逆算し、プライオリティをつけて、やる/やらない を明確にすることで乗り越えました。
これによって部分的ながら、販売実績とWebの接触データがつながることで、JTB独自のセグメントを探索できるようになりました。この時点ではAdとの連携やMAが未整備であったため、施策は手動で行っています。
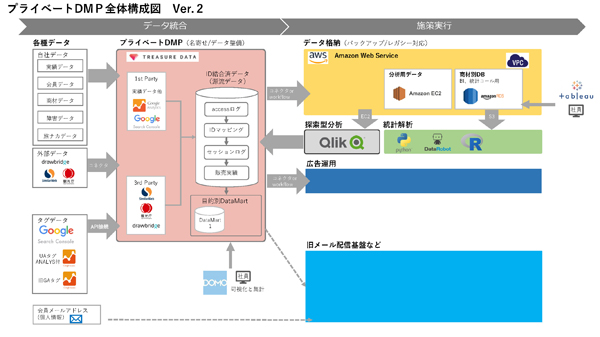
V.2.0は、3点のバージョンアップを施しています。
- 販売データソースとWebログデータの中間処理の高度化/精緻化
- AWSを採用したバックアップ基盤の整備、および統計解析アプリケーションの接続
- 旧CRMとMAツールとDMPの接続
V.1.0では、販売データとWebログデータの中間処理は最低限で行っていました。そのため、V.2.0では前処理しておいた方が良いものや、今後を見据えたテーブル設計といったデータの整備を行っています。また、データのバックアップを行うと同時に、分析アプリケーションが参照する先として組み換えを行いました。さらに、旧施策系基盤と部分的な接続を行い、リストのやり取りを開始しています。
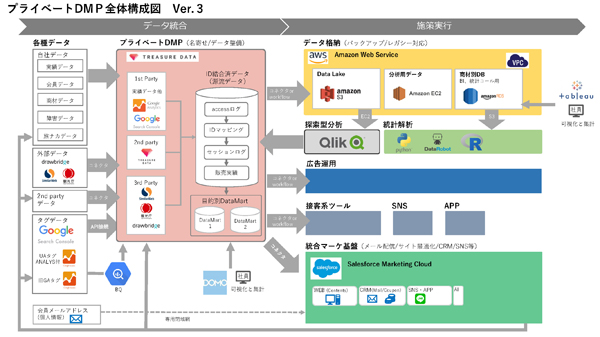
V.3.0では、施策側の導入と連携がメインになっています。プライベートDMPと各アプリケーションの導入と接続を行っており、アプリケーション選定から導入PMまでをデータサイエンスセントラルが行っています。統合マーケ基盤として、Salesforce Marketing Cloud(以下、SFMC)を採用し、旧マーケティング基盤からSFMCへ施策の移行や再現を経て、施策の自動化が可能になりました。これにより、分析チームが構築した大量のセグメントに、個別に1to1マーケティングを仕掛けられるようになったのです。
読者のなかには「なぜ統合マーケ基盤の構築を後に回したのか?」という疑問をお持ちになった方もいるかもしれません。先ほど、プライベートDMPの設計におけるキーワードは「施策から逆算すること」と書きました。つまり、どのツールがJTBに適しているか? という答えは、セグメント(分析)単位のコミュニケーション戦略にあり、総体的にそれが実現しやすいものを選び、運用する必要があったのです。
それは言い換えれば、プライベートDMPのエコシステムの設計は、施策につなげるためのセグメント構築=「探索型分析」が握っているということでもあります。
